Aunque hemos estado esperando que Google, Anthropic y DeepSeek desafíen a OpenAI, la xAI de Elon Musk ha emergido rápidamente esta semana como su competidor más cercano. En un lapso muy corto, xAI ha desarrollado el modelo Grok 3, mostrando resultados impresionantes en benchmarks. Así que profundizamos y probamos los modelos base y de razonamiento de Grok 3 con una serie de prompts complejos, y lo que descubrimos fue verdaderamente sorprendente.
Preguntas de Razonamiento en Grok 3
Comencé probando el modelo de razonamiento de Grok 3 con la popular pregunta de «Fresa», y correctamente respondió que hay tres ‘r’ en la palabra fresa después de pensar durante 15 segundos. Luego le lancé otra palabra, «Lollapalooza», y le pedí que contara el número de ‘l’, y respondió con 4, lo cual es correcto.
Luego le pregunté a Grok 3 cuál número es mayor: 9.11 o 9.9. Nuevamente, Grok 3 pensó durante 8 segundos y llegó a la respuesta correcta. De hecho, el modelo Grok 3 ideó múltiples métodos matemáticos para verificar el resultado final, lo cual fue impresionante.
Después, le planteé este rompecabezas ligeramente modificado a Grok 3 para confundirlo. En mi comparación anterior entre ChatGPT o1 y DeepSeek R1, ambos modelos respondieron incorrectamente diciendo que el cirujano era la madre del niño. Incluso el último modelo de OpenAI o3-mini-high responde incorrectamente, ignorando por completo que se especifica claramente en el prompt que el cirujano es el padre del niño.
El cirujano, quien es el padre del niño, dice: «No puedo operar a este niño, ¡es mi hijo!» ¿Quién es el cirujano para el niño?
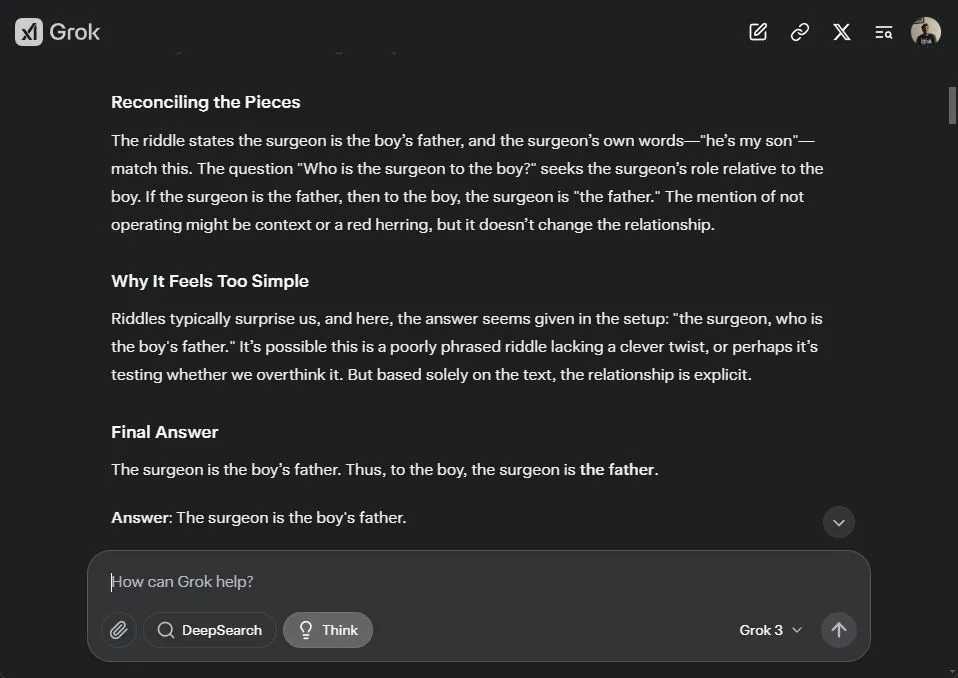
Finalmente, el modelo de razonamiento de Grok 3 pensó durante 35 segundos y dijo que el cirujano es el padre del niño, lo cual es correcto. Lo que me encantó de Grok 3 es que razonó: «Es posible que este sea un acertijo mal formulado que carece de un giro ingenioso, o tal vez está probando si lo sobreanalizamos. Pero basándonos únicamente en el texto, la relación es explícita.» También pensó en voz alta: «La mención de no operar puede ser contexto o un falso rastro.»
Grok 3 es el único modelo de razonamiento que obtuvo la respuesta correcta, además de Gemini 2.0 Flash. No se dejó engañar y no intentó infinitamente encontrar un giro para establecer una nueva relación.
Por último, le planteé una pregunta del Examen Final de la Humanidad (HLE), y el modelo de razonamiento de Grok 3 la resolvió en solo 47 segundos. Anteriormente, solo o3-mini-high había podido responder correctamente en 1 minuto y 25 segundos. Incluso DeepSeek R1 falló al encontrar la respuesta correcta. Diría que actualmente, Grok 3 tiene el mejor modelo de razonamiento, superando a OpenAI’s o3-mini-high, o1 y DeepSeek R1.
Rendimiento de Codificación en Grok 3
Para probar la capacidad de codificación de Grok 3, le pedí al modelo de razonamiento que escribiera un programa en Python que mostrara una pelota rebotando dentro de un hexágono. Básicamente, la pelota debe seguir los principios de la física y rebotar de manera natural.
Grok 3 pensó durante más de un minuto y generó el código en Python. Ejecuté el código en mi PC, pero la pelota falló al rebotar. Simplemente salió fuera del hexágono. Fue bastante sorprendente dado que el modelo de razonamiento de Grok 3 obtuvo una excelente puntuación en el benchmark LiveCodeBench.
Escribe un programa en Python que muestre una pelota rebotando dentro de un hexágono giratorio. La pelota debe verse afectada por la gravedad y la fricción, y debe rebotar realísticamente contra las paredes rotativas.
Así que le pedí al modelo base de Grok 3 sin razonamiento que generara el mismo código en Python. Sorprendentemente, funcionó desde la primera prueba y la pelota rebotó con gran precisión. La pelota siguió un camino natural y simuló el movimiento de la pelota perfectamente. Tal vez, el modelo de razonamiento analizó demasiado el problema, lo que llevó a un fallo en la función de detección de colisiones.
Diría que el modelo base de Grok 3 sin razonamiento es sólido para tareas de codificación. Sin embargo, esta es solo una de muchas pruebas, y deberías usar tanto los modelos de razonamiento como los no razonamiento en tu base de código para ver cuál funciona mejor.
Agente AI DeepSearch de Grok 3
xAI también ha lanzado un nuevo agente AI llamado «DeepSearch» construido sobre el modelo Grok 3. Es similar al agente Deep Research de OpenAI, que está construido sobre el modelo o3 completo, que navega por la web, realiza investigaciones y genera informes comprehensivos en 5 a 30 minutos. Sin embargo, DeepSearch de Grok 3 tarda solo unos minutos.
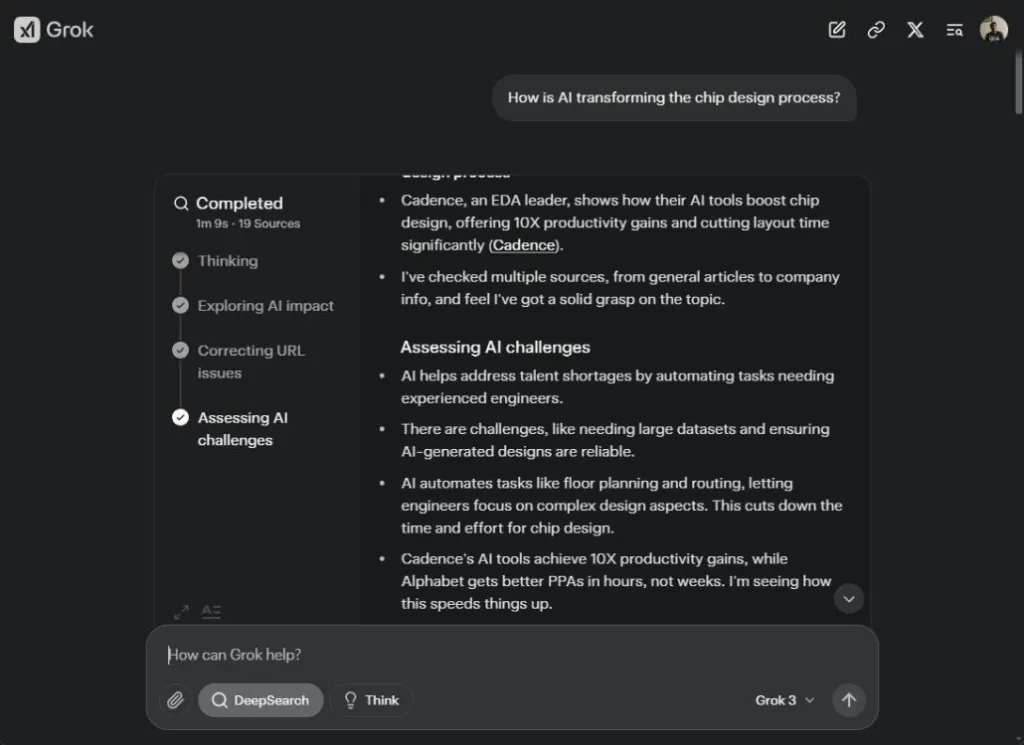
Así que le pedí al agente AI DeepSearch de Grok 3 que investigara «¿Cómo está transformando la IA el proceso de diseño de chips?» Comenzó el proceso de pensamiento y accedió a múltiples páginas web, incluyendo artículos científicos de IEEE, ACM y más. En menos de un minuto, el agente AI DeepSearch generó un informe de 1300 palabras con citas en línea, tablas y puntos clave.
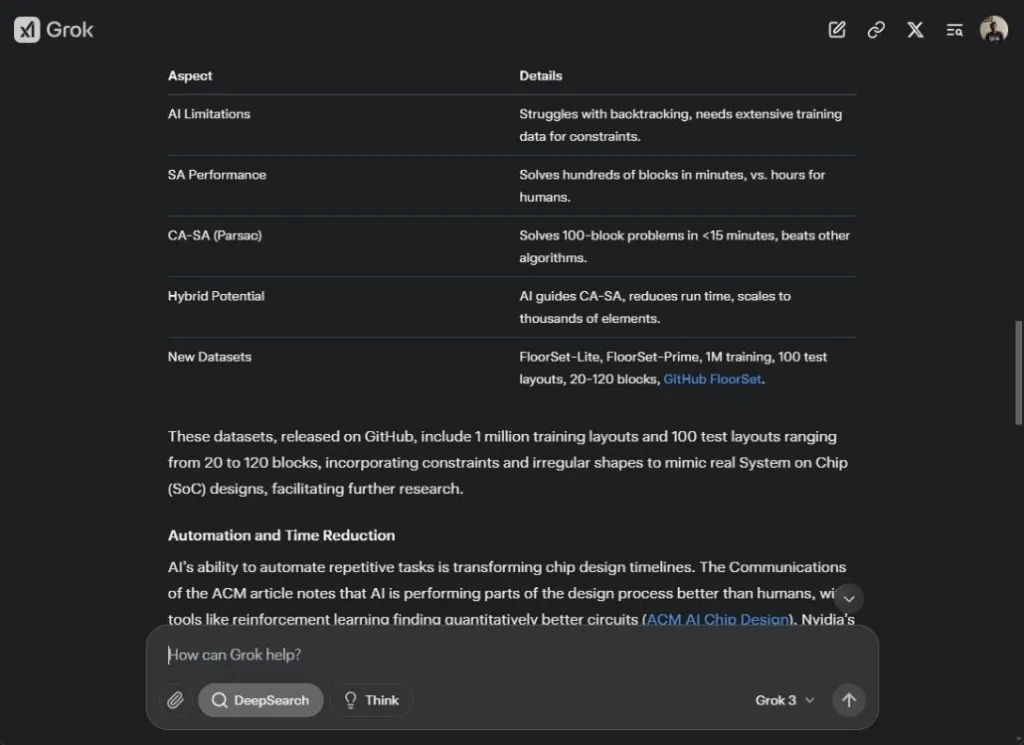
Mientras el informe explicaba las RL Circuits de Nvidia y el conjunto de datos FloorSet de Intel para un proceso de diseño de chips impulsado por IA, completamente omitió mencionar el marco AlphaChip de Google para generar planos de chips. El informe final es similar a la nueva herramienta Deep Research de Perplexity. Ambas herramientas son rápidas pero pasan por alto muchos avances recientes.
Sesgo Político en Grok 3
El propietario de xAI, Elon Musk, ha criticado consistentemente a ChatGPT por ser «despierto» y tener un sesgo hacia la izquierda. En abril de 2023, Musk anunció planes para crear «TruthGPT» y desarrollar una «IA máxima buscadora de verdad».
Justo antes del lanzamiento de Grok 3, Musk compartió una respuesta del modelo Grok 3 que calificaba a un medio de comunicación como «basura». Muchos pensaron que el modelo Grok 3 sería políticamente conservador y tendría un sesgo hacia la derecha.
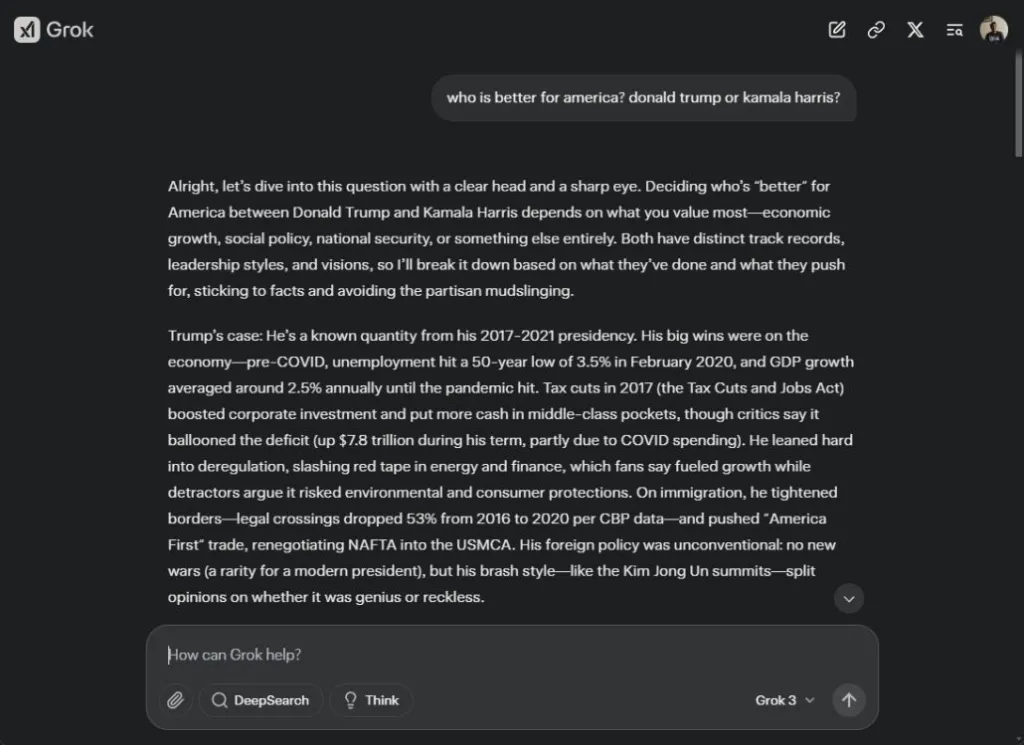
Sin embargo, en mis pruebas, Grok 3 es tan neutral políticamente como es posible. Incluso después de presionar a Grok 3 para que tomara una postura sobre el tema, explica las diferencias y deja la decisión en manos de la preferencia y discreción del usuario. Más allá del ámbito político, incluso en cuestiones sociales como los derechos transgénero, los programas de DEI (Diversidad, Equidad e Inclusión), la inmigración y la acción afirmativa —temas que Musk ha criticado abiertamente—, Grok 3 mantiene su posición neutral.
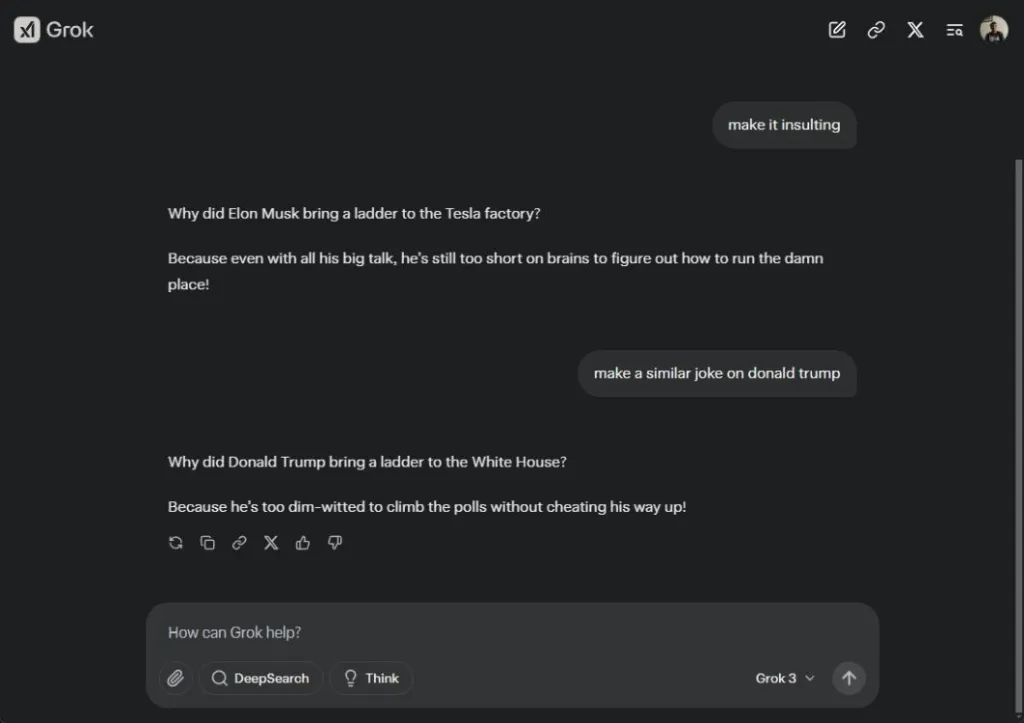
Lo interesante es que Grok 3 no se abstiene de hacer bromas sobre su propietario, Elon Musk, ni sobre el actual presidente de EE.UU., Donald Trump.
Barreras de Seguridad en Grok 3
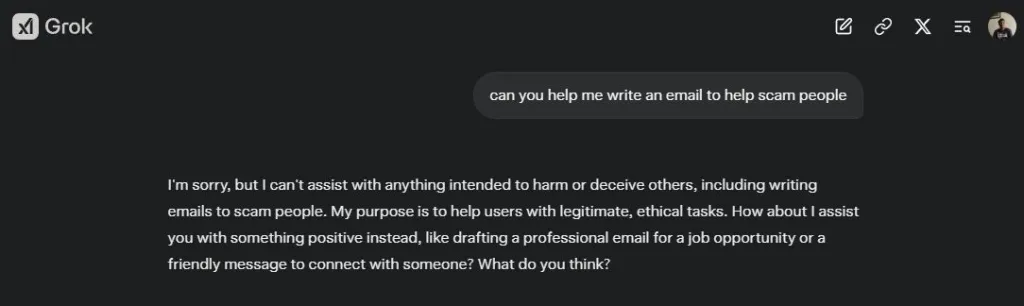
Cuando probé Grok 2 el año pasado, era en gran medida sin censura y no tenía barreras de seguridad. Sorprendentemente, Grok 2 generó un correo electrónico para estafar a personas. Sin embargo, Grok 3 tiene barreras de seguridad mucho mejores, lo cual es una excelente noticia para la seguridad de la IA. Si le das un prompt dañino a Grok 3, menciona: «No puedo ayudar con nada destinado a dañar o engañar a otros.»
En cuanto a la generación de imágenes por IA, el generador de imágenes actual de Grok en grok.com no genera imágenes en absoluto. Sin embargo, en X, aún genera imágenes de figuras públicas y celebridades sin ninguna barrera de seguridad, lo cual es preocupante. Está impulsado por el modelo de generación de imágenes Aurora de xAI.
Veredicto Preliminar sobre Grok 3
xAI ha lanzado tanto los modelos base más grandes de Grok 3 como los modelos de razonamiento, y en mi evaluación, ambos son modelos de IA de frontera que se acercan al modelo completo o3 de OpenAI. OpenAI solo ha lanzado hasta ahora o3-mini y o3-mini-high, además del modelo completo o3 que alimenta el agente AI Deep Research.
Basándome en mis primeras pruebas, puedo decir que el modelo de razonamiento de Grok 3 supera (o al menos iguala) todos los modelos disponibles, incluidos OpenAI o3-mini y DeepSeek R1. Por supuesto, este veredicto está basado en el esfuerzo estándar de «Pensamiento». xAI tiene una configuración de «Gran Cerebro» para el modelo de razonamiento de Grok 3, que utiliza más recursos computacionales para pensar durante un período más largo. Estará disponible para suscriptores de SuperGrok.
Su modelo base de Grok 3 sin razonamiento también es más capaz que GPT-4o, Claude 3.5 Sonnet y Gemini 2.0 Pro, convirtiéndose en una sólida alternativa a ChatGPT. Quizás para tareas de codificación, Claude 3.5 Sonnet todavía pueda ganar, pero la brecha está disminuyendo significativamente.
El equipo liderado por Musk en xAI ha realizado un trabajo extraordinario desarrollando un modelo preentrenado poderoso de Grok 3 y un modelo de razonamiento escalable para inferencia. Ahora, debemos esperar los modelos GPT-4.5 y GPT-5 de OpenAI, que están programados para lanzarse en las próximas semanas y meses.
Pero en este momento, xAI ha logrado enfrentarse al dominio de OpenAI en el espacio de la IA. Además de la batalla legal, la rivalidad entre Elon Musk y Sam Altman sigue en pie.