
Si has estado siguiendo la IA últimamente, sabes que el razonamiento es la próxima gran cosa. Los modelos de IA ya no solo completan oraciones: están resolviendo problemas, tomando decisiones y pensando en escenarios complejos. Ahora, el nuevo Gemini 2.5 Pro de Google ha entrado en la arena, alegando que está fuera de todos los demás modelos de AI de razonamiento.

Entonces, ¿qué hay de nuevo en Gemini 2.5 Pro? ¿Y cómo se compara realmente con otras modelos Top como O3 Mini, Deepseek R1 y Grok 3 de Openii? Los probé a todos usando indicaciones del mundo real.
¿Qué es Gemini 2.5 Pro?
Google acaba de dar a conocer su modelo de IA más potente: Gemini 2.5 Pro. Es un modelo de razonamiento, por lo que puede resolver problemas complejos al pensar paso a paso para alcanzar una respuesta lógica. Entiende las entradas multimodales, como texto, imágenes, audio y video. Actualmente está disponible para los usuarios avanzados de Gemini y es gratuito para probar en el estudio de inteligencia artificial de Google.
Gemini 2.5 obtuvo un 18.8% en el último examen de la humanidad, el más alto entre todos los modelos de razonamiento sin usar herramientas o búsqueda. HLE es un riguroso punto de referencia diseñado para evaluar el razonamiento de nivel experto de los modelos de IA en varios temas. Para el contexto, O3 Mini obtuvo el 14%, y Deepseek R1 obtuvo un puntaje de 8.6%.
Gemini 2.5 Pro también venció a otros en múltiples puntos de referencia y afirmó ser mucho mejor en el razonamiento y la codificación. En Lmarena, donde los usuarios votan por la mejor respuesta, Gemini 2.5 Pro encabezó la tabla con un puntaje de 1,443, más alto que cualquier otro modelo de IA. El único modelo que lo superó en una prueba fue el modelo de investigación profunda de Chatgpt con el 26.6%, pero ese no es un modelo de razonamiento.

Esto es de lo que necesitas entusiasmarte en Gemini 2.5 Pro:
- Sobresale en las habilidades de codificación: El modelo Gemini 2.5 Pro tiene un razonamiento mucho mejor en la codificación. Puede codificar simulaciones complejas, juegos y demostraciones con facilidad.
- Soporte estable de 1m-token: El modelo admite 1M tokens, subiendo hasta 2 millones pronto. Los modelos más antiguos técnicamente admitieron el contexto 1M, pero 2.5 lo maneja de manera más confiable y a escala. Entonces, si está cargando documentos largos o proyectos de código, este modelo funcionará mejor.
- Comprensión multimodal: No solo funciona con imágenes y audio, sino que los comprende mejor que los modelos anteriores. Al generar código para simulaciones y demostraciones, su comprensión visual juega un papel importante.
Como puede ver, la principal ventaja del modelo es la codificación, especialmente cuando están involucrados la lógica y la comprensión multimodal. Entonces, veamos cómo funciona en las pruebas del mundo real en comparación con otros modelos de razonamiento populares.
Gemini 2.5 Pro vs Otros modelos de razonamiento de IA
Dado que el modelo es fuerte en la comprensión y codificación multimodal, comencé probando esas áreas.
1. Simulación de cubos de Rubik (prueba de código)
Primero, proporcioné un mensaje detallado para crear una simulación de cubos de Rubik con opciones de Scramble y Resolver. Lo pedí en P5.js sin HTML y enumeré todas las características, funciones y herramientas técnicas necesarias para crear las animaciones.
Para mi sorpresa, Géminis entregó. Si bien la opción Resolver no funciona perfectamente, pude girar manualmente el cubo y usar la opción Scramble con éxito.
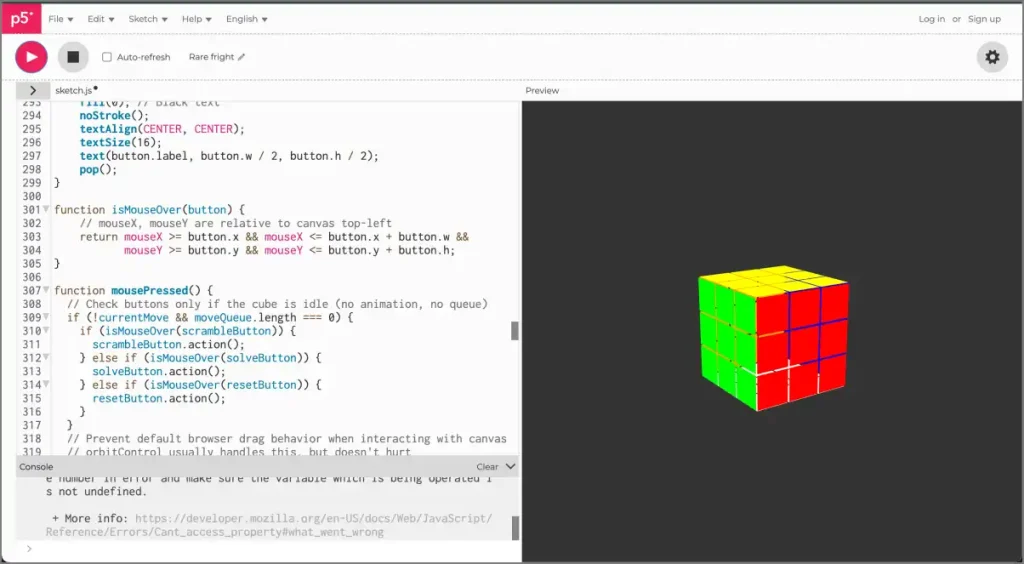
También lo probé con otros modelos, pero ninguno de ellos entregó los resultados adecuados. Para ser franco, Gemini 2.5 Pro es el primer modelo en obtener las simulaciones y las demostraciones correctas. En pocas palabras, esto no era posible con ningún otro modelo de IA antes.
2. Rompecabezas lógico (prueba de razonamiento)
También probamos algunas indicaciones basadas en el razonamiento. Aquí hay uno. Esta pregunta no tiene una respuesta definitiva:
En una isla, cada habitante es un caballero, que siempre dice la verdad, o un bribón, que siempre miente. Conoces a tres habitantes: A, B y CA dice: «B es un bribón». B dice: «C es un caballero». C dice: «A es un caballero». ¿Quién es qué?
Veamos qué modelo puede averiguar que se trata de una paradoja. Géminis tardó solo 24 segundos en identificar que es una situación paradójica sin una respuesta clara. O3 Mini y Grok de OpenAI tomaron alrededor de 40 segundos y predijeron la respuesta correcta. Deepseek R1, sin embargo, tomó 434 segundos y se equivocó la primera vez, aunque lo hizo bien cuando se le preguntó nuevamente.
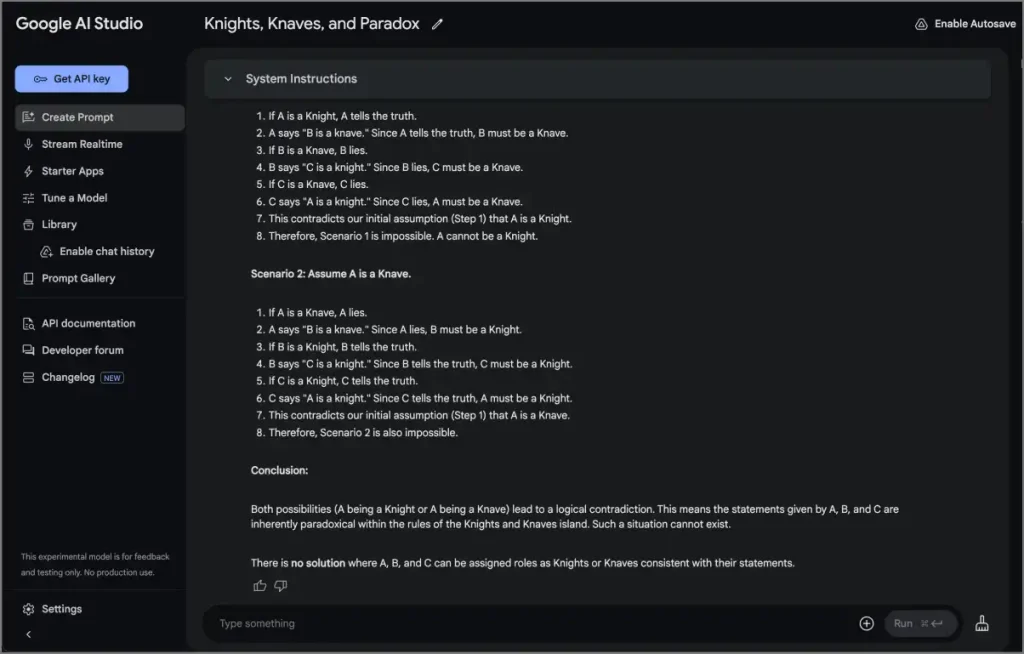
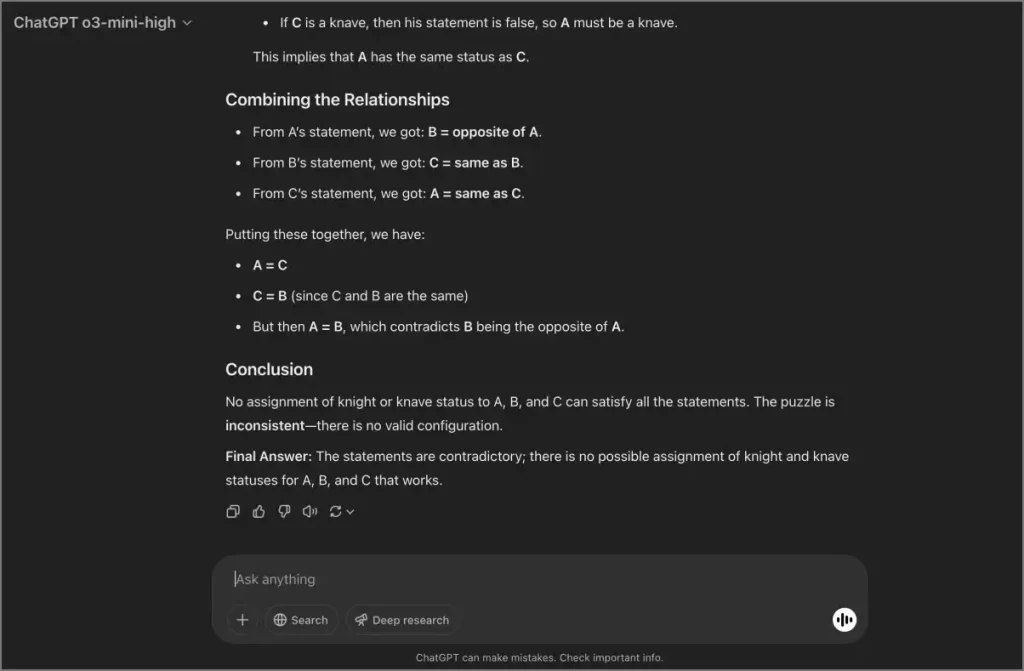
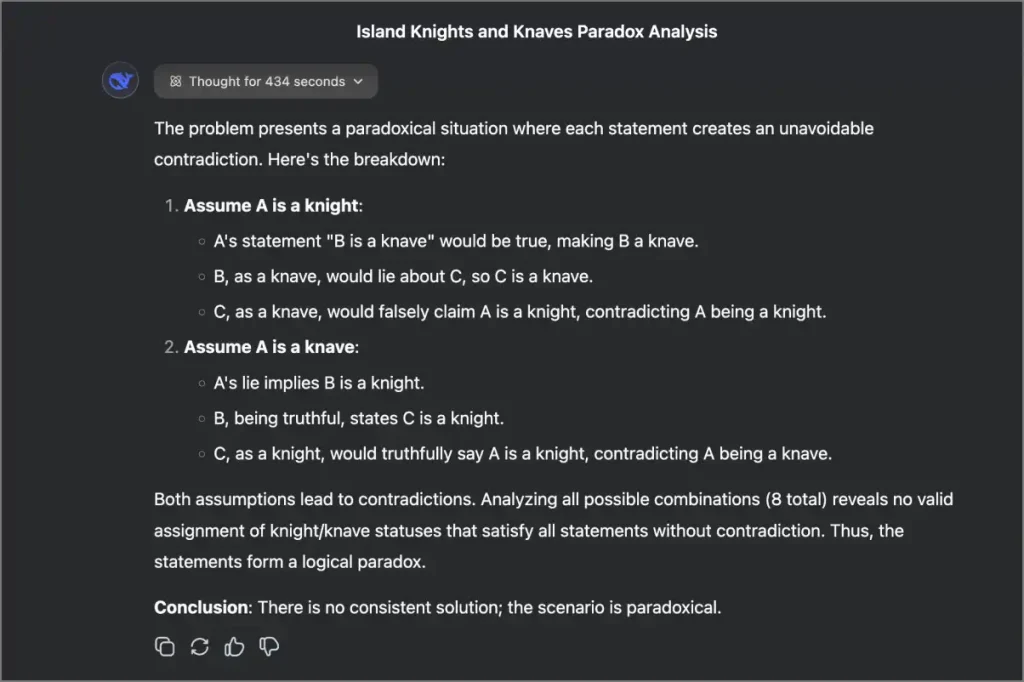
Este no es solo un caso único. Deepseek tiende a tropezar con preguntas más complejas. Dicho esto, la diferencia general no es enorme, ya que la mayoría de los modelos predijeron correctamente las respuestas utilizando la lógica en la mayoría de los casos.
3. Problema de física (prueba de matemáticas)
A continuación, probé todos los modelos con algunas pruebas de matemáticas. O3 Mini ha liderado las matemáticas hasta ahora, sin embargo, Gemini 2.5 Pro obtuvo mejores puntos de referencia. Aquí hay un ejemplo de todos.
Un tren de alta velocidad se mueve a una velocidad constante de 0.9c a través de un túnel que tiene 2 kilómetros de largo (medido por un observador estacionario). ¿Cuánto tiempo toma el tren para pasar por el túnel de acuerdo con un observador estacionario? ¿Cuánto tiempo pasa para un pasajero sentado en el tren (considerando la dilatación del tiempo)?
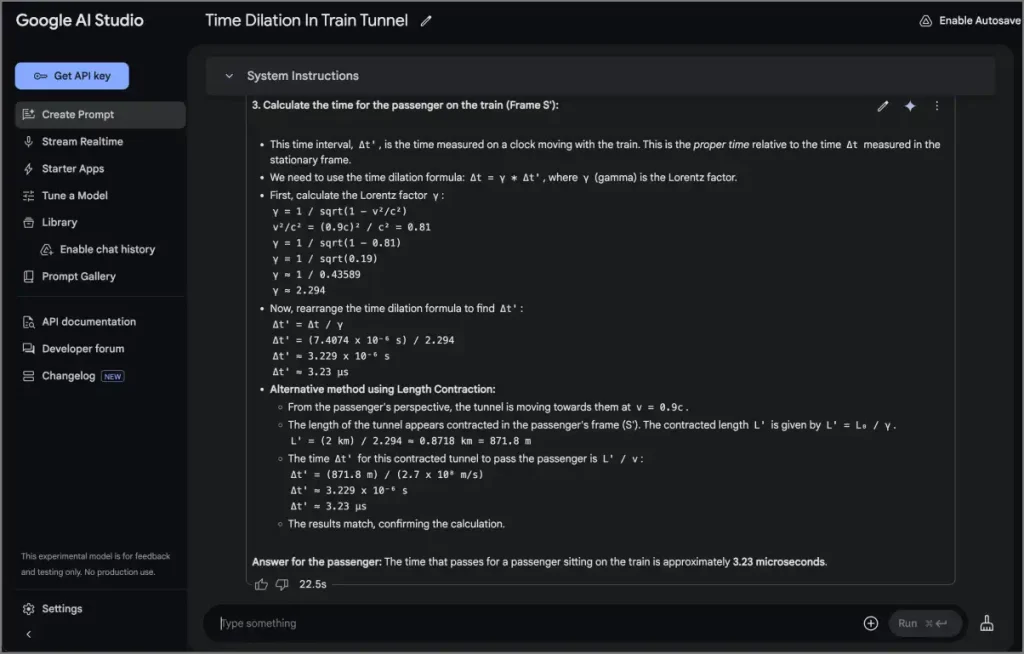
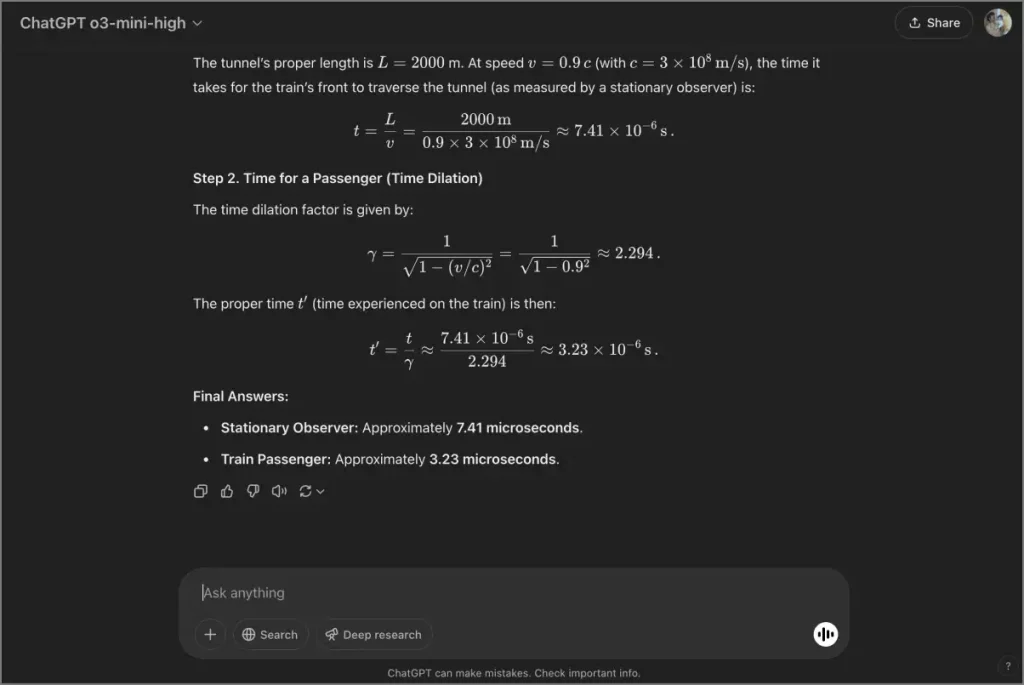
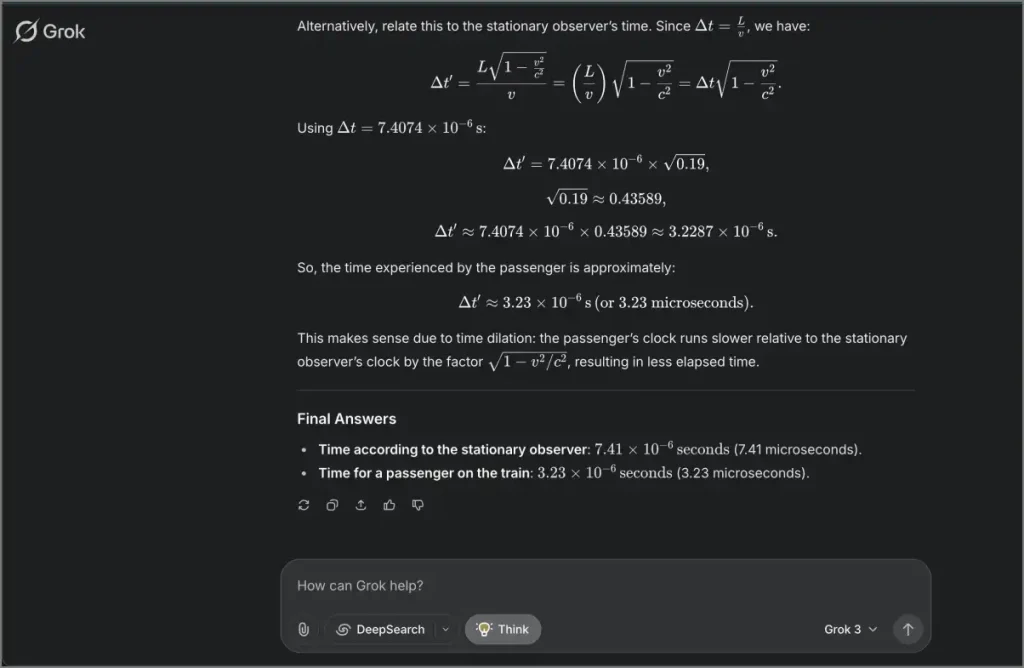
Todos los modelos resolvieron esto con precisión y proporcionaron explicaciones claras y paso a paso. Si bien Gemini lidera en puntos de referencia de matemáticas, la brecha de rendimiento real es mínima: todos los modelos manejaron bien la mayoría de los problemas.
Géminis 2.5 Pro
Gemini 2.5 Pro es una mejora masiva sobre 2.0 pensamiento flash. Sin embargo, está más o menos en el mismo nivel que modelos como O3 Mini, Grok 3 o Deepseek R1. Dicho esto, cuando se trata de comprensión multimodal, este modelo finalmente ofrece resultados mucho mejores. Aparte de eso, ahora podemos decir que Géminis se ha unido oficialmente al nivel de otros modelos cuando se trata de razonamiento.


